

Tokenmaxxing is dying, and Chinese open-source models fill the gap
Amazon, Meta, and Uber are capping the token spend as GLM-5.2 and DeepSeek give their models away for free.


Over the past week, a new Chinese model called GLM-5.2 has set off another round of alarm in Silicon Valley. Released by the company z.AI under a permissive open-source license, it takes direct aim at the coding and agentic-workflow business that Anthropic has built its reputation on — and running on a one-million-token context window, it lands surprisingly close to Claude Opus 4.8 and OpenAI’s GPT-5.5. The open-source community is ecstatic.
At the same moment, America’s “unlimited AI credits” mania is draining away. Amazon, Meta and others are killing their no-limits AI plans. After Uber’s engineers burned through a full year’s AI budget in four months, the company capped each employee at $1,500. Even Microsoft CEO Satya Nadella has warned that the industry can’t let a few AI giants swallow the whole economy.
The link between open-source models and what people now call “Tokenmaxxing” is simple enough: programmers burn too many tokens, the bills get too big, and faced with a mountain of invoices, people reach for the open-source option.
This is not the Tokenmaxxing takedown you’ve read on Substack, though. Because a few questions kept nagging at me. If open-source models can do the job, why is anyone still topping up their Claude account? And if everyone runs to open-source, how does anyone building a model make money?
It was only after GLM-5.2 shipped that I arrived at a first answer. Both of these waves — the rush to open-source and the rush to burn tokens — come down to the same thing: how we decide to think about a token.

Born Out of Scarcity
Start with the open-source side, and start with GLM-5.2.
Z.ai has released the core weights of GLM-5.2 under an unrestricted MIT license. Any company can download it free from Hugging Face, customize or fine-tune it, and run it locally or on a virtual machine. Standing the thing up is still a slog, but next to the now-delisted Fable 5, it’s a genuinely good option. The model was built on Huawei’s Ascend chips — no Nvidia hardware involved.
But GLM-5.2 is not another DeepSeek. DeepSeek’s Liang Wenfeng came out of a quant fund, is worth billions, and has chosen near-total seclusion. (He recently put about $2.8 billion of fresh money into DeepSeek)
Z.ai, by contrast, is an open-source model maker that’s already publicly listed in Hong Kong. It has no billionaire patron, and its road has been every bit as winding as DeepSeek’s.
In 2020, BAAI’s Tang Jie argued the language model still deserved the effort. Of BAAI’s 480 A100 cards, 400 went to Tang’s team.

Tang also tried Huawei’s 910A and 920 chips. On large-model training, the 920’s operator efficiency was just 18% of an A100’s; after Tang’s team helped rewrite the operators, they pushed it to roughly 40%, and trained a 13B code model, CodeGeeX.
But Tang’s real goal was 100B-parameter model, even 2,000 910A cards weren’t enough. In the end, Tang turned to z.AI, the company he’d founded back in 2018, rented 1,000 cards. In July 2022, they finally had their hundred-billion model: GLM-130B.
I tell his story because he embodies the type. Most of China’s open-source AI companies grew out of academic projects; they incorporated mainly because they needed to buy compute, and they open-sourced their architecture to keep their academic visibility.
Starved of chips, they learned to adapt to whatever domestic silicon they could get. Z.ai wasn’t placed on the U.S. entity list until 2025, but it was already optimizing for Huawei chips in 2020. Localized compute and open architecture became, almost by default, the signature of Chinese AI.
The open-source bet has its skeptics inside China, too. In 2024, Baidu founder Robin Li argued that closed models were more powerful and cheaper to run than open ones. His point being that closed models came with more compute and bigger teams, and that ERNIE was nearly a match for ChatGPT. (A little ironic, isn’t it?) ERNIE was not, in fact, in ChatGPT’s league, and China never produced a closed model strong enough to make Li’s case.
Turning open-source into profit is a hard problem. In a 2025 interview, a z.AI expert described the company’s three possible lanes — inference, agentic, and coding — and said z.AI chose coding. MiniMax, by contrast, chose multimodal AI and AI companionship. At the time it wasn’t an obvious call: z.AI’s business leaned on enterprise and government contracts, coding showed no clear path to profit, and multimodal could win consumers directly. Z.ai was not the favorite.
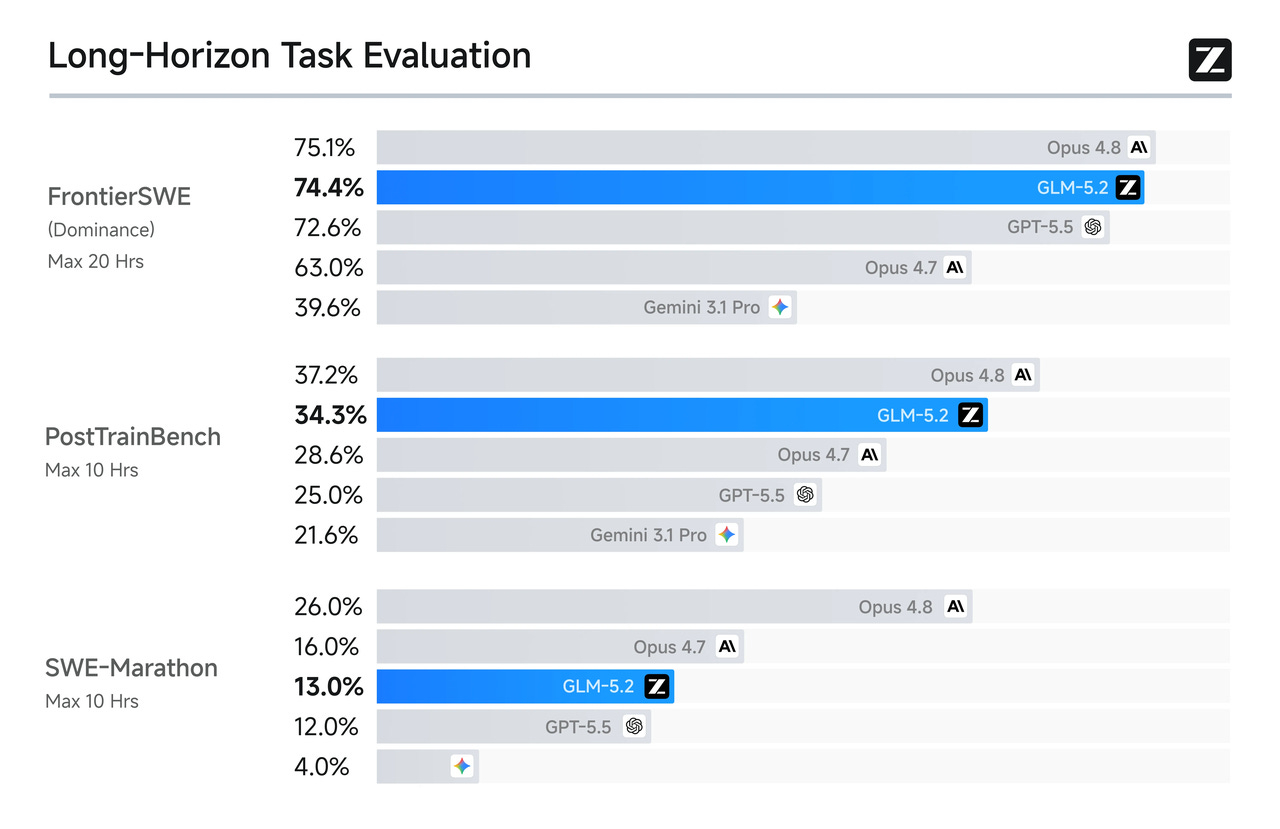
Then the AI-coding boom arrived. Z.ai’s latest results show a net loss of about ¥3.18B ($444M)against R&D spending of roughly ¥3.2B($444M). Still in the red — but strip out the open-ended spend on compute, and z.ai’s revenue can cover day-to-day operations. If it can get cheaper chips, or use its chips more efficiently, or land a wave of enterprise buyers, the losses could narrow. That would be good news.
In a sense, z.AI may owe Anthropic a thank-you note: both for the AI-doom evangelism and for the AI-coding fervor. Anthropic’s strong models cultivated customers, and its incessant messaging then drove some of them away. One of the places those customers landed was z.AI.
A first conclusion, then: going open-source is a passive choice: a Chinese model maker admitting, out loud, that it’s behind on both compute and model quality. But if closed-model progress stalls, users won’t keep paying premium prices for closed-model tokens; they’ll choose open-source on their own. The Chinese saying fits: just hold your plate steady, and the roast duck falls from the sky.
Water, Electricity, and a Bad Analogy
Now the other wave : Tokenmaxxing.
GLM-5.2, DeepSeek and Kimi are mostly catching customers who fled the bills. But if OpenAI and Anthropic were good enough, would open-source still persuade anyone?
Then Alibaba gave me a frame. In a March internal memo, CEO Wu Yongming argued that in the AI era, the token would become a basic factor of production, the way traffic was in the internet era. Alibaba set up the Alibaba Token Hub (ATH) around that idea.
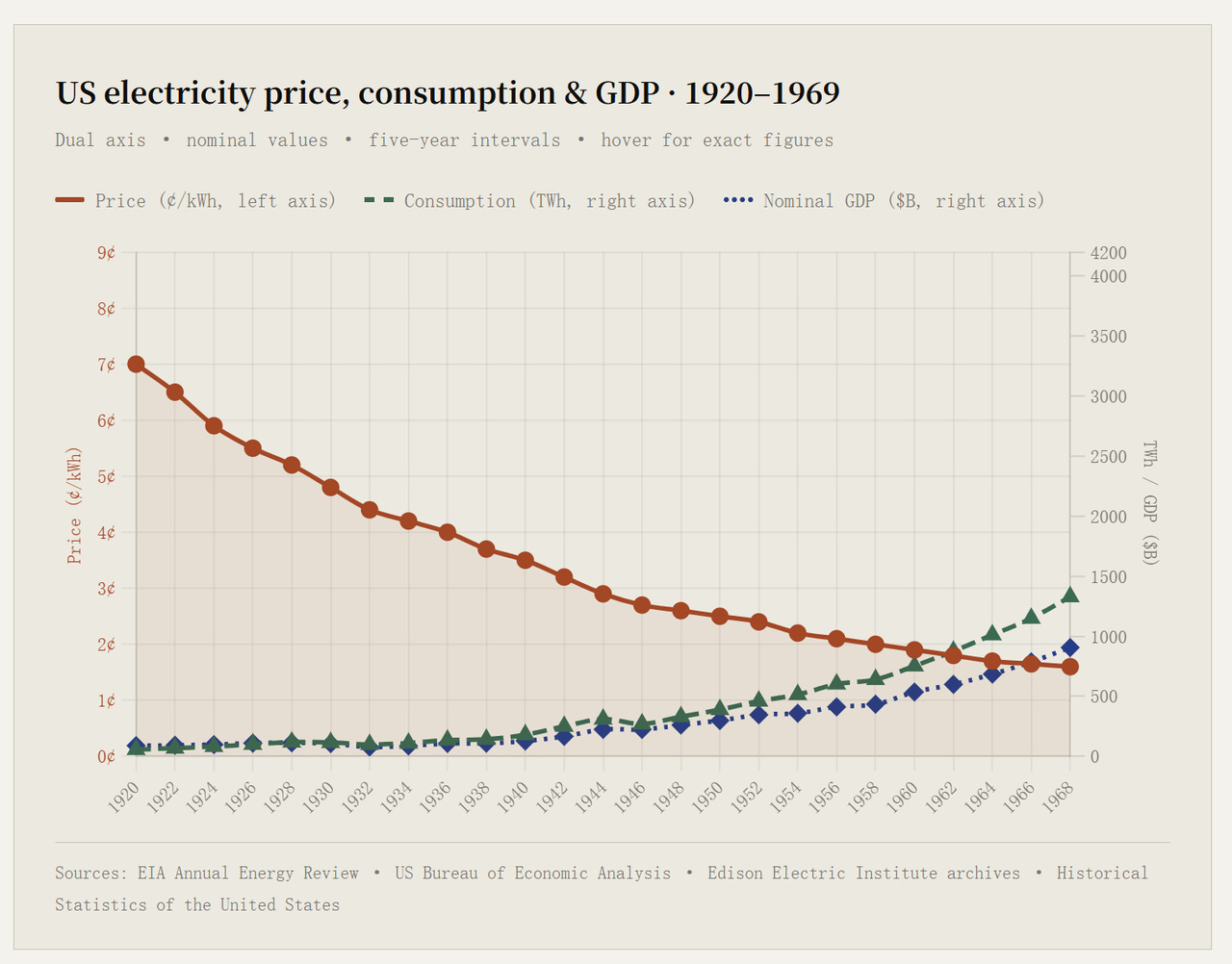
Follow the logic. In the age of electrification, a country’s electricity output and its GDP growth tend to rise together — no nation ever went bankrupt building power plants. So I looked at U.S. electricity prices, consumption and GDP from the 1920s to the 1960s.
As prices fell, total spending on electricity rose 6.2x, but nominal GDP rose 11.1x. Americans spent relatively less on power and got more output for it.
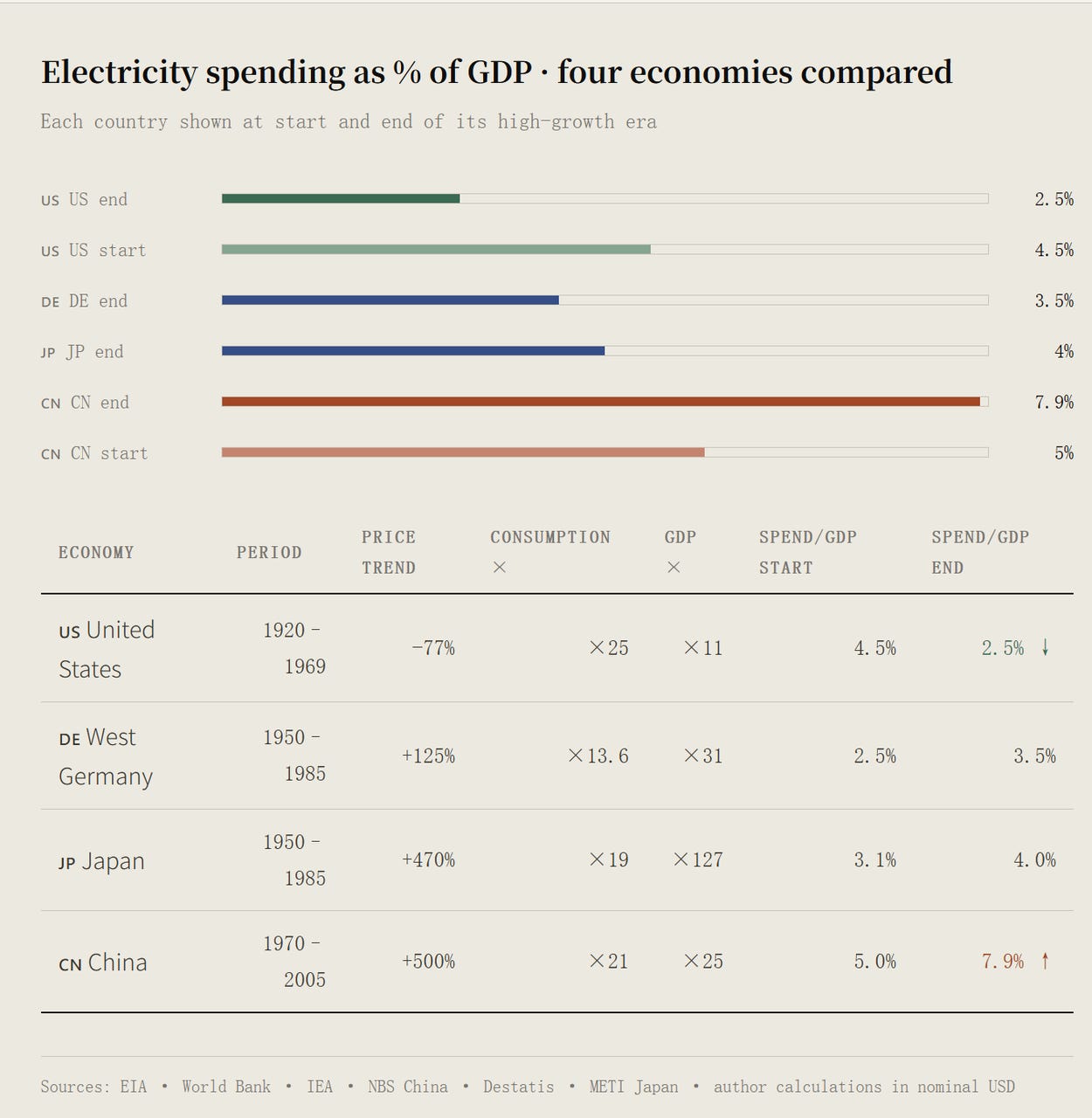
The pattern doesn’t always hold cleanly, though. Through the fast-industrializing decades in Japan, China, and West Germany, electricity spending actually outran GDP. But in West Germany and Japan, even during those high-growth years, the share of GDP eaten by electricity fell sharply to almost 2.0%.
That suggests is a kind of lag: a rising industrial economy takes roughly fifteen years to work through the adjustment and reach the point where cheap power finally translates into abundant output.
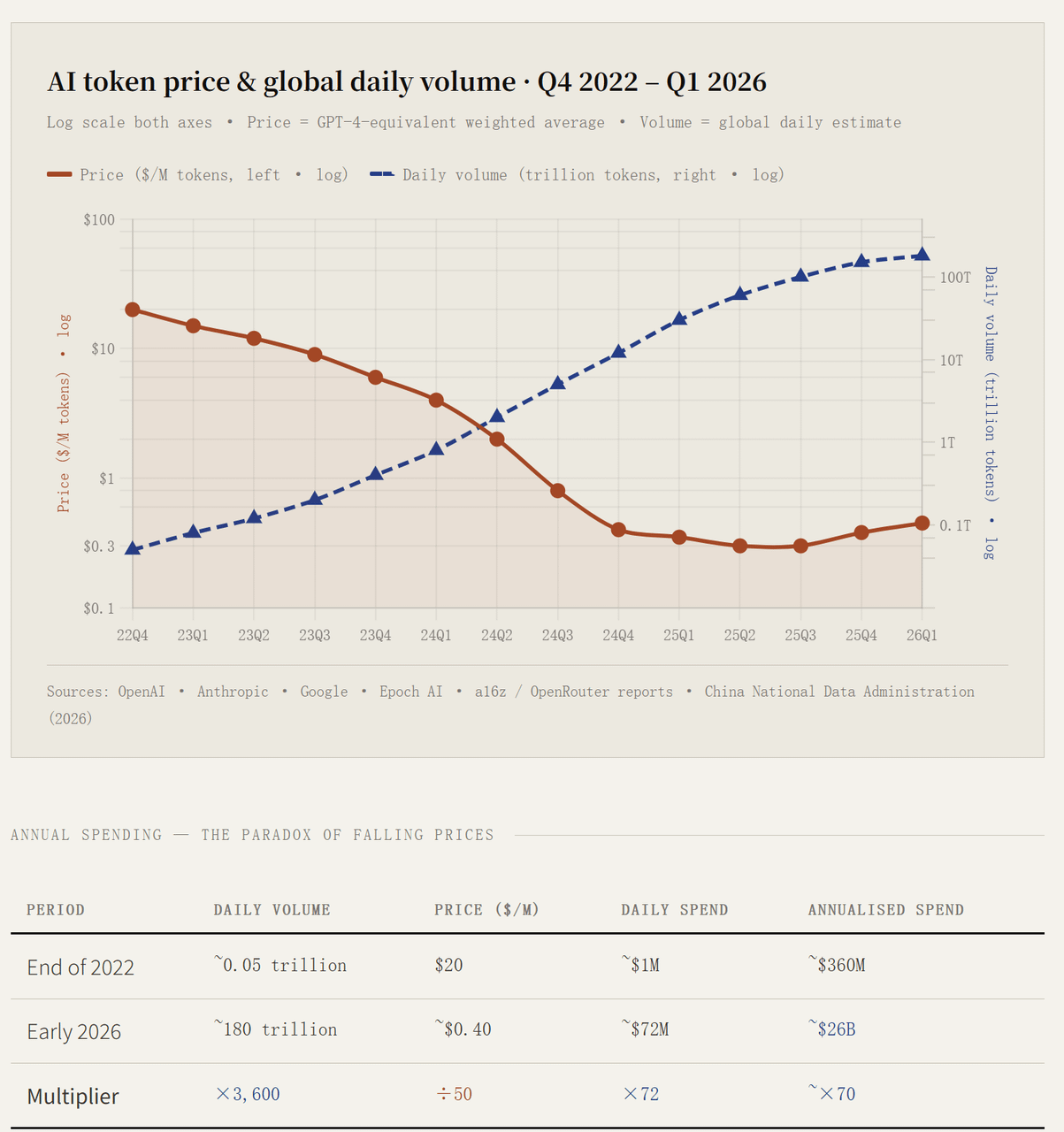
If Wu is right and tokens really are AI’s water and electricity, they ought to deliver something similar. But run the numbers and the story breaks. Over the past four years, the cost of a given unit of AI dropped more than 90 percent, while total token spending rose 70x. My god.
If this is water and electricity, the bill is climbing far too fast. A seventyfold jump in token spending over four years has not produced anything like a matching surge in what society actually makes. Yes, the data centers went up, and the chips are back-ordered for months. But none of it has meaningfully improved the quality or efficiency of production outside the AI industry itself.
What breaks the “AI as utility” analogy is the reasoning model. Across coding and agentic tasks, a model now generates thousands of internal reasoning tokens before it answers, pushing single-task consumption 10 to 100 times higher than older models.
So how much does all that buy you? In an NBER paper, DeMiller, Musolff and Yang measured the gains from AI coding tools across four stages of work:
Writing a single file: +290%
Bulk work: +150%
A specific deliverable: +50%
A shipped, delivered product: +30%
In other words, even in coding — the thing AI does best — the gains shrink fast as you zoom out from a single file to a finished product. Optimizing the whole pipeline is far harder than optimizing one slice of it.
Three Months of Unlimited Tokens
As latecomers, Chinese firms tried to copy the Tokenmaxxing wave too. Per public reports in March, Tencent gave core R&D teams an annual token package worth about $31,700 each, plus $1,000 a month for outside tools; ByteDance opened its internal AI tools for unlimited use and reimbursed half of employees’ personal AI experiments, capping technical staff at $1,000 a year; Baidu handed engineers unlimited ERNIE access plus up to $800 a year for outside tokens; 360 simply loaded every employee with 100 million tokens.
The recalibration came fast. Three months later, Tencent’s Hunyuan team was capped at roughly $970 worth of outside models, and everyone moved onto quotas — though using Tencent’s own Hunyuan model stayed unlimited. ByteDance staff likewise faced no limit on its in-house TRAE tool. Internally, Tencent came out against usage rankings, refusing to treat token consumption as a single yardstick for output.
The reason was simple: Chinese companies wanted real output, and they weren’t seeing it. One employee, speaking anonymously, described a team that built workflows across several different models — only to find the AI-generated pieces wouldn’t fit together, and to scrap the whole thing and start over. Twenty-odd people spent about $6,900 in tokens in a month and had nothing to show for it. At some firms, the free tokens got quietly repurposed — for analyzing stocks, say — and the company had no idea where they’d gone.
Meta is tightening what employees can spend on Anthropic and other providers — a sharp reversal from the scene a few months earlier, when staff competed to burn tokens. Bloomberg has reported that Uber and Walmart each capped AI coding-tool use; the Financial Times reported that Amazon scrapped the internal leaderboard that ranked employees by AI usage.
A June report from the consultancy Bain, titled Your AI Budget Is Growing. Your Returns Aren’t. Here’s Why., found that among companies able to quantify AI’s cost savings, 40 percent saw actual savings of 10 percent or less. Of the 37 percent who’d targeted savings of 11 to 20 percent, only 31 percent actually got there.
The grassroots buying isn’t over, though. One ByteDance engineer pays for Claude Max — $100 a month reimbursed — to write what he considers the cleanest code. Better than DeepSeek, by his lights, and GLM he can’t get. But one employee’s purchase doesn’t make the whole company better off. Tokenmaxxing shifts an individual’s cost onto the employer.
The irony is that the last firm into the water was the first one out. Tencent, a relative laggard in China’s AI race, quit Tokenmaxxing earlier than anyone. ByteDance is still touting its numbers: as of June, it says, daily token calls to its Doubao model topped 180 trillion, up more than tenfold in a year.
Not a Currency
Looking across both waves, I went hunting for the common thread, and found this question: can a token serve as the industry’s equivalent — its currency?
For a token to work like, say, gold, it would need to circulate freely, hold a relatively stable price, and trade cleanly. Tokens do none of this. They can’t be exchanged, which means tokens from a “better” model are inherently more sought-after and more expensive. They can’t circulate: DeepSeek’s tokens can’t be handed to Claude. And while usage clearly climbs, the price keeps falling.
The deeper problem: spending the same number of tokens does not buy you the same result. Get lucky, and the model produces a complete, working program. Get unlucky, and the output is riddled with hallucination. A token like that is almost impossible to price: Producing it costs money, but what it buys you is a gamble.
Tencent VP Li Qiang put the objection plainly. A token, he said, is like fuel consumption: focus only on how much you burn, and ignore the engine’s efficiency and output, and the customer eventually walks. “Switching costs are tiny. Whoever’s cheaper gets the business. This is not a sticky business.”
Nadella made the same point obliquely. He named no one, but he argued that a handful of companies have captured most of the value AI creates, while relentlessly hyping AI’s safety risks and the prospect of mass unemployment — and using that fear to demand enormous resources and chase limitless expansion. You can’t claim every white-collar job is about to vanish, and that AI might even become a weapon, he said, and in the same breath demand all the electricity to build your data centers. Microsoft, it’s worth noting, was an early OpenAI investor.
It’s hard to picture the cautious conservatives among China’s and America’s tech giants landing on nearly identical complaints about token abuse and unchecked AI expansion. But if they have, it’s a sign the expansion frenzy has hit its ceiling.
That’s not so strange. Consider Cursor, one of the great token-burners. It had a standing relationship with Anthropic — Anthropic supplied the compute, Cursor consumed it. Then Claude Code arrived, Anthropic cut off a key chunk of Cursor’s token supply, and Cursor turned, for a stretch, to the Chinese open-source model Kimi. Cursor wasn’t praising Chinese open-source; it was pushed toward Kimi by Anthropic. A company that grabs its own customers’ business to make money is a dangerous company. Anthropic, plainly, is a little dangerous.

Microsoft is working to cut token costs through action: using an optimized DeepSeek V4, or other cheaper open-source models, as a more economical option inside Copilot Cowork. AI, Nadella has said, should become a company’s knowledge engine, with the firm flexibly calling on a range of models by price and performance, which means models that “keep climbing and improving inside a machine the company itself controls.”
China has a name for the model-selling business: model-as-a-service (MaaS). Alibaba’s ATH is essentially an integration of the entire stack: chips, cloud, and the models themselves. Tencent offers a token-consumption platform where you can call its Hunyuan model and DeepSeek. The word “token” is still in the name, but they’ve clearly repackaged the thing as something more like enterprise cloud or office software.
We’ve seen this movie before. When cloud computing arrived a decade ago, China had a cloud craze too, and the hot product was the personal cloud drive: Pay for a membership, get online storage. Selling a virtual one-terabyte drive for a few hundred yuan was never going to survive on consumers alone. Cloud’s real endgame was each major vendor building its own native cloud service, aimed squarely at enterprise and government.

Amid all the token chaos, I find one rare patch of calm, because DeepSeek drew a floor. Per million tokens: cached input about $0.0035, input about $0.42, output about $0.83. DeepSeek issued just two terse notices. The first: we’re trying a price cut. The second: the cut is permanent.
That fits what I’ve observed of Liang Wenfeng. He treats DeepSeek as an academic research project. He isn’t short of money, he doesn’t go around selling its grand vision, and so DeepSeek carries far less of the a16z scent. Which is quietly turning it into something unexpected — a piece of infrastructure that could underpin every intelligent application. If that happens, the token really might become AI’s basic fuel.
As I write this, the world’s models are still in a brutal token price war. Gemini‘s token prices have fallen 60 to 80 percent; OpenAI is weighing big cuts to what it charges users.
But I still haven’t seen a Chinese AI income statement I’m happy with. What puzzles me: ByteDance’s Doubao assistant, its TRAE coding tool, and its Seedance video model have piled up users — but how much those users actually pay is unknown. By ByteDance’s own December 2025 figures, only about 100 external customers had consumed more than a trillion tokens cumulatively. Set against the more than $27.8 billion ByteDance may spend on AI this year, the paying behavior of all these users is worth watching closely — and that’s before you subtract what Doubao spends on ads in China’s airports and on the Spring Festival Gala.
Curiously, China’s National Data Administration publishes official token statistics. Daily token calls in China rose from 100 billion in early 2024 to 100 trillion by the end of 2025, and past 140 trillion by the end of this March — equivalent, the agency notes, to roughly a quadrillion Chinese words a day.
But it added a caveat:
“We must also recognize, clearly, that the sharp growth in token usage reflects the scale and popularity of AI applications — and is not entirely the same thing as original innovation capacity.”
Closing Note
I’m a cautious skeptic of the AI industry. The caution comes from a fear of any “non-physical-output” business: if it can’t improve the efficiency or quality of something physical, I will doubt this.
We can treat Tokenmaxxing as a social experiment. But it’s an experiment run at the cost of violent disruption to society itself—people lose jobs, farmland is torn up. In under five years, the combined market value of OpenAI and Anthropic went from zero to nearly $2 trillion. And still there’s no equivalent, society-wide bump in GDP to show for it.
Tokens are the resource AI runs on, but it’s a resource we can’t yet put a value on—or at least, we don’t know what it’s worth. It takes hundreds of thousands of dollars in GPUs to produce, and sells to users for a few cents. The AI companies believe that once tokens are cheap enough, people will find ways to use them. The question is how long we have to wait. At the current rate of cost growth, the runway for token economics is only getting shorter.
Tokenmaxxing is usually traced to a Meta leaderboard, but the real origin is Shopify. In June 2025, Shopify engineering lead Farhan Thawar revealed that they’d first built such a board to honor the people shipping excellent AI projects. But “more tokens used = better AI work” set a bad precedent, and they shut the leaderboard down themselves. They never imagined the Tokenmaxxing wave that followed.
 | A guest post by
|